
GitHub Pages 블로그 네이버(NAVER) 검색등록하기
서론
기존에 Tistory에서 운영하던 블로그를 Jekyll 기반으로 Github Pages로 블로그를 이전하였다. 블로그 운영의 자유도를 높이기 위해서 블로그를 이전한 이후 여러가지 많은 일을 하게되었다. 그 중에 하나가 바로 검색 문제이다. Google 검색엔진은 sitemap을 등록하여 검색엔진에 내 블로그 정보를 제출수 있었다. 국내 사용자가 가장 많이 사용하는 Naver에서는 검색등록과 네이버 웹 마스터도구로 등록할 수 있는데 내 사이트를 네이버 검색엔진에 검색등록하는 방법을 소개하려고 한다.
검색등록
Naver에서는 검색엔진에 검색되지 않은 사이트들 등록신청을 받고 있다. 만약 내 사이트가 네이버에서 검색을하더라도 나오지 않는다면 검색등록을 신청하면 된다.
https://submit.naver.com/regist.nhn

Naver는 다양한 검색등록을 제공하고 있다. 업체 검색을 위한 등록신청이 있고 내 홈페이지를 등록신청하는 것도 있다. 블로그를 등록하기 위해서 내 홈페이지 등록신청을 한다. 내 홈페이지 URL과 전화번호를 입력하고 Naver에서 사이트를 검토하고 등록을 진행하는 방식이다.

등록신청이 끝나면 하루내 등록이 되거나 검토가 끝나는대로 검토가 완료되어 검색에 반영되었다는 메일이 온다.

아쉽게 제목에 어파스트로피(‘) 표시가 자동으로 삭제되어져버린다. 등록은 saltfactory’s blog라고 신청했는데 saltfactorys blog로 자등으로 등록되어버린다. 네이버에서는 왜 이렇게 했는지 모르겠다… 이것이 있고 없고의 차이는 아주큰데 왜 이렇게 구현했을까… 아직도 의문스러운 부분이다.
이렇게 등록되면 Naver 검색엔진에서는 등록이 되지 않는다. 이 부분도 궁금한 부분이다. 완벽하게 단어가 맞아야만 나오는 검색엔진이라니…
saltfactory’s blog로 검색을 하면 사이트가 나오지 않는다. 검색엔진 등록후 크라울링된 데이터에서 텍스트를 찾아서 나오긴 하지만 검색등록한 사이트를 찾은것은 아니다.

saltfactorys blog로 검색을 하면 검색등록한 사이트가 검색이 된다. 하지만 saltfactory’s blog와 saltfactorys blog는 의미가 다르다.

어쩔 수 없이 검색등록한 사이트의 제목을 변경신청했다. 검색등록 수정을 하기 위해서 는 등록한 URL과 전화번호를 입력하고 등록확인을 선택한다.

제목을 변경하고 확인 버튼을 선택한다.


네이버 웹마스터 도구
Naver에서는 좀 더 고급스럽게 웹 사이트 검색을 관리할 수 있는 네이버 웹마스터도구 서비스를 오픈하였다.

위에 검색등록은 사이트를 검색에 등록하는 것이다. 위의 검색데모를 보면 알겠지만 등록한 사이트명으로 사이트가 검색이 되는 것이다. 좀더 검색을 세밀하게 하기 위해서 검색엔진이 내 사이트내의 글을 수집하도록 해야한다. 이것을 네이버 웹마스터도구로 요청할 수 있다.
웹마스터 도구에 로그인을 한 후 사이트를 등록한다.


등록된 사이트를 클릭하면 검색엔진이 데이터를 수집한 현황을 보여준다. 아래 사진은 이미 등록한 상태에 캡쳐를 한 것이라 이런 수집 결과를 볼 수 있지만 처음 사이트를 등록하면 수집 데이터는 나오지 않는다.
웹 마스터도구는 다음을 제공한다.
- 전체현황 : 수집된 페이지의 전체 현황을 살펴볼 수 있다.
- 수집현황 : 수집설정한 내용에 따라 검색엔진이 사이트에서 수집한 페이지의 현황을 살펴볼 수 있다. 검색엔진로봇 수집 페이지 수, 신디케이션 문서, 페이지 다운로드 크기 정보를 제공한다.
- 오류현황 : 검색엔진이 사이트에 페이지를 수집하면서 발생한 오류 페이지 리스트를 보여준다.
- 수집요청 : 검색엔진이 사이트에서 수집하는 방법을 설정할 수있다. 단순 URL 수집 요청하거나 신디케이션 핑 전송 요청, RSS 요청, 사이트맵(sitemap.xml)요청 을 기반으로 검색엔진이 검색을 할 수 있게 설정할 수 있다.
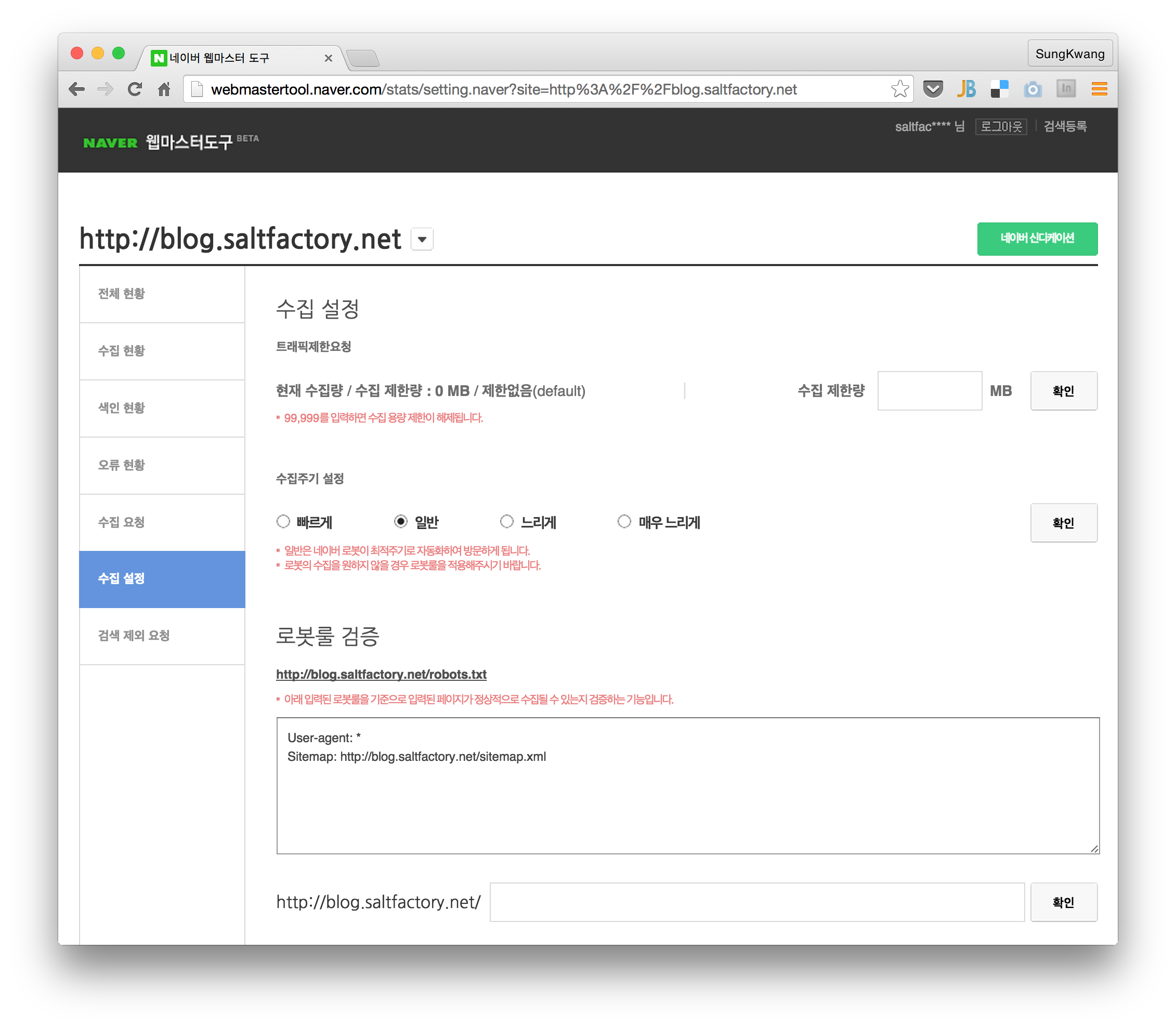
- 수집설정 : 검색엔진 로봇이 사이트에 검색할 때 수집하는 로봇을 수집을 설정할 수 있다. 트래픽제한, 수집주기, 로봇 룰을 요청할 수 있다.






네이버 신디케이션
네이버 웹 마스터도구는 네이버 신디케이션 기능을 제공한다. 이 기능은 ATOM포멧으로 사이트 정보를 만들어서 네이버에 제출하는 방법이다.
웸 마스트도구의 네이버 신디케이션 버튼을 클릭하면 다음과 같은 화면이 나타난다. 네이버 신디케이션을 사용하기 위해서는 연동키(token)이 필요하다. 이 연동키는 이후에 네이버 쪽으로 신디케이션 정보를 제출할 때 사용한다.

네이버 신디케이션으로 정보를 제출하기 위해서 네이버 서버가 내 사이트의 신디케이션 정보를 구독하기 위한 xml 문서가 필요한디 이 문서는 ATOM 기반으로 만들어져야한다.
네이버에서는 네이버 신디케이션을 위해 XML 문서 스키마를 정의하여 배포하고 있다.
네이버 신디케이션 스키마 : http://webmastertool.naver.com/syndi/syndi.xsd
<?xml version="1.0"?>
<xs:schema
xmlns="http://webmastertool.naver.com"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://webmastertool.naver.com"
elementFormDefault="qualified">
<xs:annotation>
<xs:documentation>
elements for syndication
</xs:documentation>
</xs:annotation>
<xs:simpleType name="content-attr-type">
<xs:restriction base="xs:string">
<xs:enumeration value="html" />
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="summary-attr-type">
<xs:restriction base="xs:string">
<xs:enumeration value="text" />
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="feed-link-attr-type">
<xs:restriction base="xs:string">
<xs:enumeration value="site" />
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="entry-link-rel-attr-type">
<xs:restriction base="xs:string">
<xs:enumeration value="via" />
<xs:enumeration value="mobile" />
<xs:enumeration value="app" />
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="entry-link-type-attr-type">
<xs:restriction base="xs:string">
<xs:pattern value="(playstore|itunes|nstore):.*" />
</xs:restriction>
</xs:simpleType>
<xs:complexType name="author-type">
<xs:sequence>
<xs:element name="name" type="xs:string" />
<xs:element name="url" type="xs:anyURI" minOccurs="0" />
<xs:element name="email" type="xs:string" minOccurs="0" />
</xs:sequence>
</xs:complexType>
<xs:element name="feed">
<xs:complexType>
<xs:sequence>
<xs:element name="id" type="xs:anyURI" />
<xs:element name="title" type="xs:string" />
<xs:element name="author" type="author-type" />
<xs:element name="updated" type="xs:dateTime" />
<xs:element name="link" minOccurs="0">
<xs:complexType>
<xs:attribute name="rel" type="feed-link-attr-type" />
<xs:attribute name="href" type="xs:anyURI" />
<xs:attribute name="title" type="xs:string" use="optional" />
</xs:complexType>
</xs:element>
<xs:choice minOccurs="0" maxOccurs="unbounded">
<xs:element name="entry">
<xs:complexType>
<xs:sequence>
<xs:element name="id" type="xs:anyURI" />
<xs:element name="title" type="xs:string" />
<xs:element name="author" type="author-type" />
<xs:element name="updated" type="xs:dateTime" />
<xs:element name="published" type="xs:dateTime" />
<xs:element name="link" maxOccurs="unbounded">
<xs:complexType>
<xs:attribute name="rel" type="entry-link-rel-attr-type" />
<xs:attribute name="href" type="xs:anyURI" />
<xs:attribute name="title" type="xs:string" use="optional" />
<xs:attribute name="type" type="entry-link-type-attr-type" use="optional" />
</xs:complexType>
</xs:element>
<xs:element name="content">
<xs:complexType mixed="true">
<xs:attribute name="type" type="content-attr-type" />
</xs:complexType>
</xs:element>
<xs:choice minOccurs="0" maxOccurs="unbounded">
<xs:element name="category">
<xs:complexType mixed="true">
<xs:attribute name="term" type="xs:string" />
<xs:attribute name="label" type="xs:string" use="optional" />
</xs:complexType>
</xs:element>
<xs:element name="summary">
<xs:complexType mixed="true">
<xs:attribute name="type" type="summary-attr-type" />
</xs:complexType>
</xs:element>
</xs:choice>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="deleted-entry">
<xs:complexType>
<xs:attribute name="ref" type="xs:anyURI" />
<xs:attribute name="when" type="xs:dateTime" />
</xs:complexType>
</xs:element>
</xs:choice>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
이 스키마를 잘 살펴봐야한다. <xs:sequence>로 정의한 부분은 반드시 순서대로 정의해야한다. 예를 들어 저자 정보를 가지는 author를 살펴보면 순서가 name, url, email이라는 것을 확인할 수 있다. minOccurs=0 이라는 말은 생략할 수 있는 엘리먼트이다. 이 순서를 지키지 않으면 유효성 검사에서 에러 결과를 받게 된다.
<xs:complexType name="author-type">
<xs:sequence>
<xs:element name="name" type="xs:string" />
<xs:element name="url" type="xs:anyURI" minOccurs="0" />
<xs:element name="email" type="xs:string" minOccurs="0" />
</xs:sequence>
</xs:complexType>
Jekyll로 블로그를 운영하고 있기 때문에 네이버 신디케이션으로 네이버 서버가 Atom 문서를 읽어가기 위해 naverfeed.xml 파일을 추가하였다. 이제 최근글 20개를 가지고 xml 문서를 만들어 낼 것이다.
---
layout: null
---
<?xml version="1.0" encoding="UTF-8"?>
<feed xmlns="http://webmastertool.naver.com">
<id>{{ site.url }}</id>
<title><![CDATA[ {{ site.title | xml_escape }} ]]></title>
<author>
<name>{{ site.author.name | xml_escape }}</name>
<email>{{ site.author.email }}</email>
</author>
<updated>{{ site.time | date_to_xmlschema }}</updated>
<link rel="site" href="{{ site.url }}" />
{% for post in site.posts limit:20 %}
<entry>
<id>{{ site.production_url }}{{ post.id }}</id>
<title><![CDATA[ {{ post.title | xml_escape }} ]]></title>
<author>
<name>{{ site.author.name | xml_escape }}</name>
<email>{{ site.author.email }}</email>
</author>
<updated>{{ post.date | date_to_xmlschema }}</updated>
<published>{{ post.date | date_to_xmlschema }}</published>
<link rel="via" href="{{ site.url }}{{ post.url }}" />
<content type="html"><![CDATA[ {{ post.content | xml_escape }} ]]></content>
</entry>
{% endfor %}
</feed>
http://blog.saltfactory.net/naverfeed.xml

문서를 만들었으면 XML검증을 진행한다. 네이버 신디케이션 페이지에서 XML검증 버튼을 클릭해서 검증 페이지를 연다.
http://webmastertool.naver.com/valid/xml.naver

그리고 네이버 서버가 구독할 xml 문서의 URL을 입력하고 확인버튼을 클릭한다. 오류가 발견되지 않으면 다음과 같이 알림창이 열릴 것이다.

이제 네이버 서버에 내 사이트의 글이 업데이트 되었다는 정보를 알려줘야한다. 이것을 네이버 신디케이션 핑이라고 말한다. 네이버 서버에게 내 사이트의 업데이트 신호를 알려주면 네이버 서버가 내 사이트의 Atom 문서를 구독해서 검색엔진에 반영하는 것이다.
터미널을 열어서 다음과 같이 curl로 바로 요청할 수 있다. 다음 옵션을 사용한다.
- -H : Authorize: Bearerr 연동키(token)
- -d : ping_url=encodedURIComponent(사이트주소)
curl -H "Authorization:Bearer AAAAO...생략...TXXmE=" -d "ping_url=http%3A%2F%2Fblog.saltfactory.net%2Fnaverfeed.xml" https://apis.naver.com/crawl/nsyndi/v2
요청이 성공적으로 끝나면 다음과 같은 결과를 받는다. 성공적인 결과는 error_code에 000 값이 존재하는 xml 결과를 받고, 문제가 발생할 경우는 에러코드가 있는 xml 결과를 받게 될 것이다.
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<result>
<message>OK</message>
<error_code>000</error_code>
<receipt_number>bb7f32b55b66a2ed0ecec120d54d53481951</receipt_number>
</result>

신디케이션 핑을 요청하면 네이버 신디케이션 페이지 하단에 마지막 핑 정보가 업데이트 된다. 다음과 같이 나타나면 핑 요청을 진행하고 있는 것이다.

네이버 서버에 핑을 요청하여 네이버 서버가 내 사이트의 문서를 수집하게 되면 다음과 같이 결과가 나타난다. 문서에 오류가 있거나 수집 실패가되면 요청실패라고 나타나고 에러를 확인할 수 있는 링크가 표시된다.

네이버 신디케이션 핑은 하루에 5000 건만 요청할 수 있다. 내 사이트가 자주 글이 업데이트 된다면 네이버 검색엔진이 내글을 빠르게 구독해서 반영하기 위해서는 내 사이트의 글이 업데이트될 때마다 네이버 서버로 핑을 요청하는 프로그램을 만들면 된다.
사이트맵 제출
네이버 검색 엔진에 내 사이트의 정보를 반영하기 위한 또 다른 방법은 내 사이트의 사이트맵을 네이버 검색엔진에 등록하는 것이다. Jekyll에는 sitemap 플러그인이 기본적으로 포함되어 있다. 블로그 URL 뒤에 sitemap.xml을 입력해보자.
http://blog.saltfactory.net/sitemap.xml

네이버 웹마스터의 수집요청 메뉴에서 사이트맵 제출에서 사이트맵을 입력하고 제출하면 된다.

RSS 등록
네이버 검색엔진이 내 사이트의 RSS를 구독하면서 검색엔진에 페이지를 반영할 수 있도록 설정할 수 있다. Jekyll을 사용한다면 다음과 같이 RSS 문서를 만들 수 있다. 만약 feed.xml 파일이 존재한다면 이미 RSS 문서가 만들어져있는 것이다. 없다면 다음내용으로 feed.xml 파일을 생성한다.
---
layout: null
---
<?xml version="1.0" encoding="UTF-8"?>
<rss version="2.0" xmlns:atom="http://www.w3.org/2005/Atom">
<channel>
<title><![CDATA[ {{ site.title | xml_escape }} ]]></title>
<description><![CDATA[ {{ site.description | xml_escape }} ]]></description>
<link>{{ site.url }}{{ site.baseurl }}/</link>
<atom:link href="{{ "/feed.xml" | prepend: site.baseurl | prepend: site.url }}" rel="self" type="application/rss+xml" />
<pubDate>{{ site.time | date_to_rfc822 }}</pubDate>
<lastBuildDate>{{ site.time | date_to_rfc822 }}</lastBuildDate>
<generator>Jekyll v{{ jekyll.version }}</generator>
{% for post in site.posts limit:10 %}
<item>
<title><![CDATA[ {{ post.title | xml_escape }} ]]></title>
<description><![CDATA[ {{ post.content | xml_escape }} ]]></description>
<pubDate>{{ post.date | date_to_rfc822 }}</pubDate>
<link>{{ post.url | prepend: site.baseurl | prepend: site.url }}</link>
<guid isPermaLink="true">{{ post.url | prepend: site.baseurl | prepend: site.url }}</guid>
{% for tag in post.tags %}
<category>{{ tag | xml_escape }}</category>
{% endfor %}
{% for cat in post.categories %}
<category>{{ cat | xml_escape }}</category>
{% endfor %}
</item>
{% endfor %}
</channel>
</rss>
내 블로그에서 RSS 주소를 열어보자.
http://blog.saltfactory.net/feed.xml

네이버 웹 마스터도구에서 수집요청 메뉴의 RSS등록에 위의 RSS 주소를 추가한다.

robots.txt 설정
마지막으로 네이버 검색엔진 로봇이 내 사이트를 탐색해서 읽어갈 수 있도록 다음과 같은 내용으로 robots.txt 파일을 생성한다.
User-agent: *
Sitemap: http://blog.saltfactory.net/sitemap.xml
내 사이트에서 이 파일을 열어보자. http://blog.saltfactory.net/robots.txt

네이버 웹 마스터 도구에서 수집설정 메뉴에 로봇룰 검증에 이 파일 주소를 입력하고 검증해보자.

수집이 가능하다면 다음과 같은 알림창이 나타날 것이다.

수집결과 검색엔진 반영
이제 네이버에서 수집된 결과를 검색엔진에 반영했는지 확인해보자. 이전에는 블로그의 글이 검색엔진에서 검색되지 않았지만 네이버 웹마스터도구를 활용하고 난 다음 다음과 같이 검색엔진에 내 블로그 글이 검색되는 것을 확인할 수 있다. 현재 시점의 내 블로그의 마지막 글을 검색했을 때의 결과이다.

하지만 자세히 살펴보면 이 글의 페이지가 아니라 내 사이트의 첫 페이지(http://blog.saltfactory.net)의 글이 검색된 것을 확인할 수 있다. 검색된 결과 옆의 저장된 페이지를 클릭하면 다음과 같이 로봇에 의해서 검색되었다는 것을 알 수 있다.
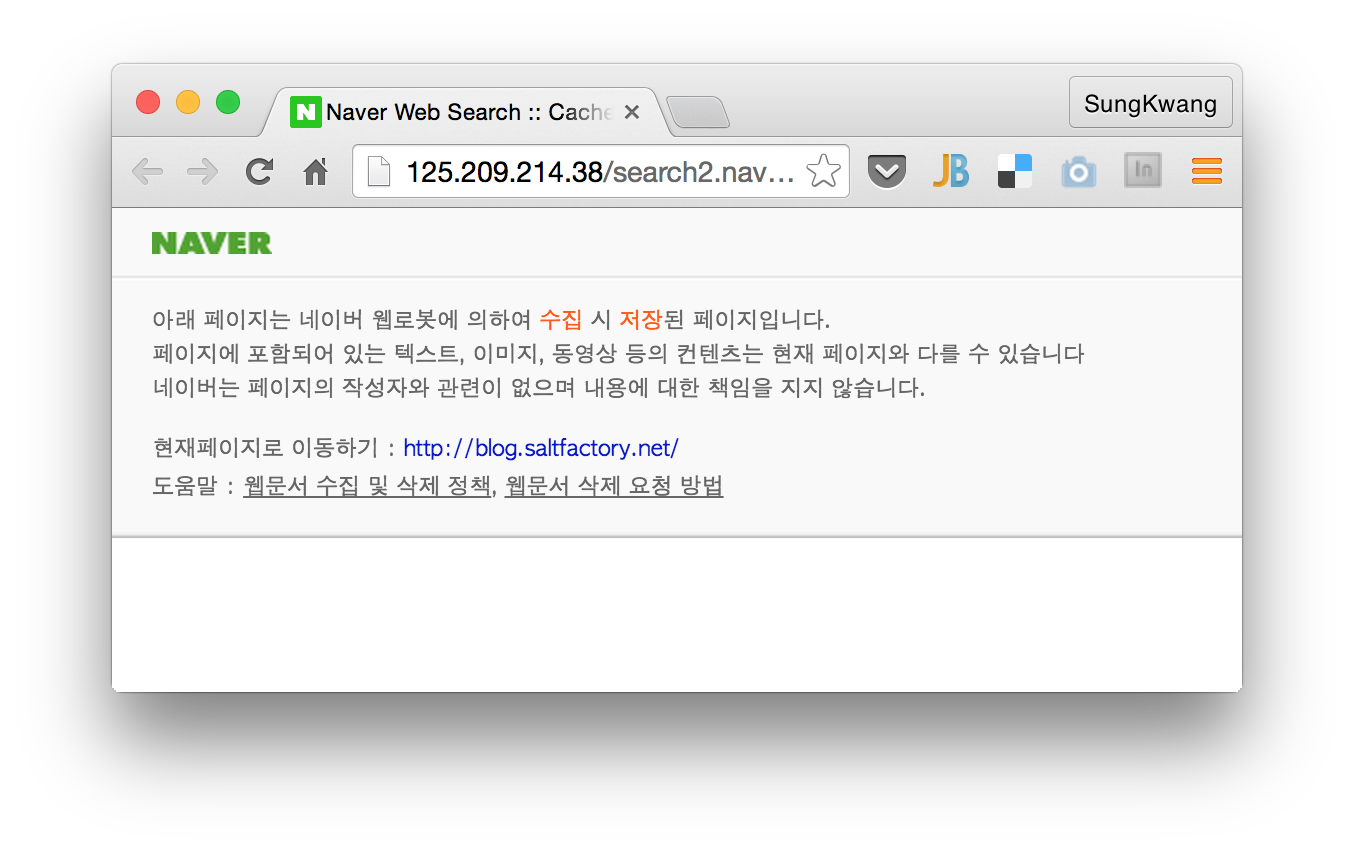
모든 검색엔진은 사이트에서 페이지를 수집해서 검색어와 페이지 후보를 만드는 색인작업을 하는데 내 블로그의 글을 수집하고 색인하는데 시간이 걸리 때문인것 같다. 네이버 웹 마스터 도구의 색인현황을 살펴보면 오늘 수집된 결과중에 아직 색인된 것이 없다는 것을 확인할 수 있다.
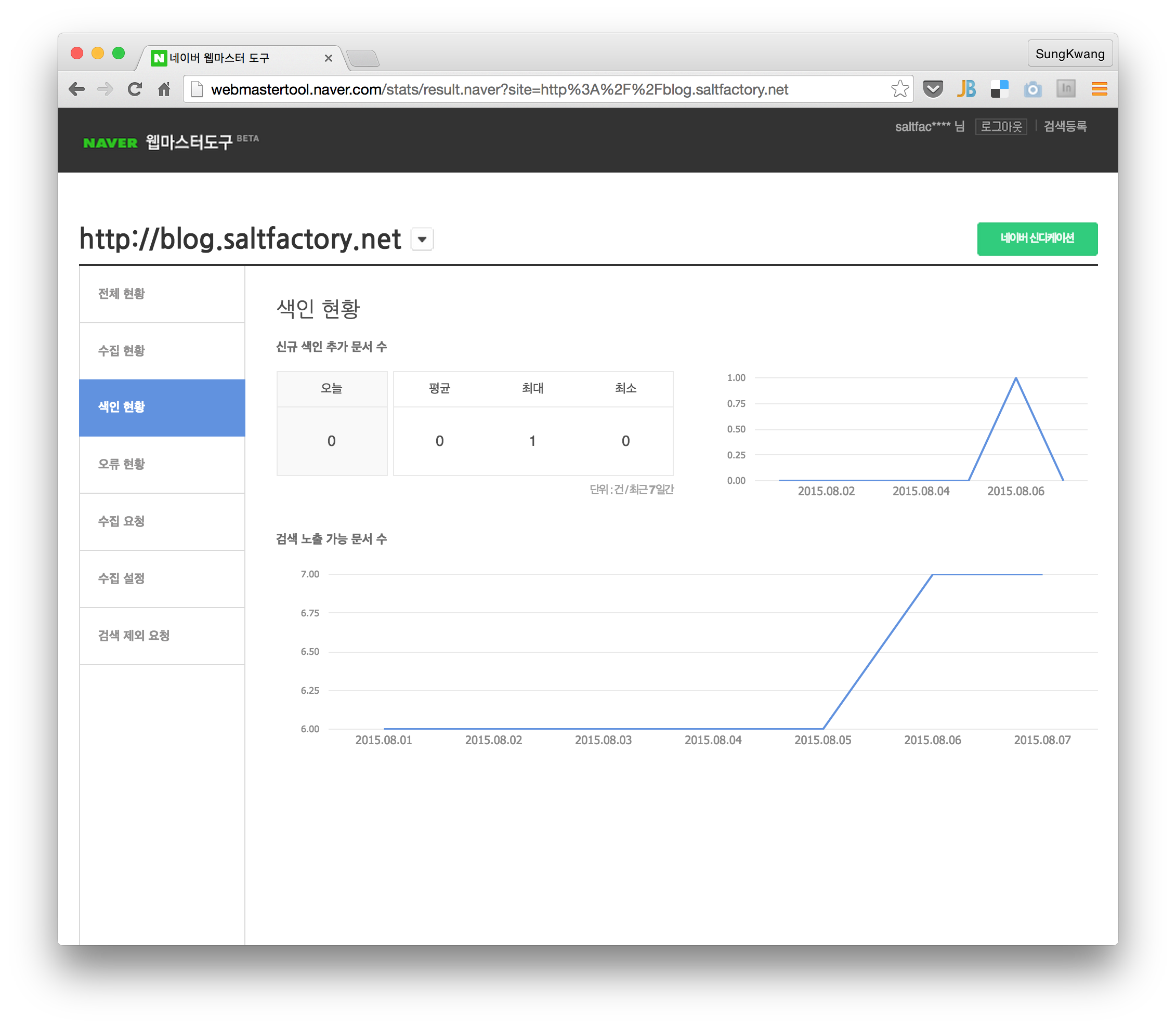
빠르면 내일? 며칠안에 색인이 되면 네이버 검색엔진에 블로그 글이 검색되어 질 것으로 기대한다.
네이버 검색등록을 할 때 사이트제목 어퍼스트로피(‘) 추가할 수 있으면 좋겠다. saltfactory’s blog로 등록하고 싶은데… 검색등록에 관해 네이버측에 메일을 보내려고 하는데 검색등록 고객센터로 메일을 보낼 수 있는 곳이 보이지 않는다. 고객센터페이지가 있고 자동화되는건 좋은데 관리자에게 바로 메일 보낼수 있으면 좋겠다.
결론
국내 사용자가 가장 많이 사용하는 Naver 검색엔진에서 내 사이트가 검색되어지는 방법을 살펴보았다. 네이버는 네이버 블로그의 글을 가장 먼저 검색하는 것 같다. 그리고 외부 블로그를 사용할 때 네이버 검색엔진이 찾지 못하면 내 글이 검색이 되지 않는다. 그래서 네이버 블로그가 아닌 블로그를 운영한다면 사용자기 직접 네이버 검색엔진이 찾을 수 있게 검색엔진에게 요청을 해야한다. 먼저 웹 사이트를 바로 검색될 수 있게 요청하는 것은 검색요청에 내 사이트를 등록하는 것이다. 그리고 네이버 웹 마스터도구를 사용하여 검색엔진 요청을 구체적으로 할 수 있다. 방법은 크게 네이버 신디케이션, 사이트맵 요청, RSS 등록, 로봇룰을 사용하여 네이버 검색엔진에게 내 사이트의 정보를 알려주는 것이다. 많은 개발자들이 Google 검색엔진을 사용하고 있지만 국내 사용자들은 Naver 검색엔진을 많이 사용하고 있다. 두 검색엔진 모두 검색 엔진이 내 사이트의 페이지를 분석하기 위해서는 사이트맵이나 다양한 방법으로 검색엔진에게 정보를 알려줘야한다. 앞으로 더 많은 사용자들이 문서를 함께 공유할 수 있기를 기대한다.
